I have recently realized that I haven’t published any post for a while, so I don’t think there is a better way to start 2017 than with a small tutorial: how to mint w3ids for your ontologies without having to issue pull requests on Github.
In a previous post I described how to publish vocabularies and ontologies in a permanent manner using w3ids. These ids are community maintained and are a very flexible approach, but I have found out that doing pull requests to the w3id repository may be a hurdle for many people. Hence, I have been thinking and working towards lowering this barrier.
Together with some colleagues from the Universidad Politecnica de Madrid, we released a year and a half ago a tool for helping documenting and evaluating ontologies: OnToology. Given a Github repository, OnToology tracks all your updates and issues pull requests with their documentation, diagrams and evaluation. You can see a step by step tutorial to set up and try OnToology with the ontologies of your choice. The rest of the tutorial assumes that your ontology is tracked by OnToology.
So, how can you mint w3ids from OnToology? Simple, go to “my repositories tab:
Then expand your repository:
And select “publish” on the ontology you want to mint a w3id:
Now OnToology will request a name for your URI, and that’s it! The ontology will be published under the w3id that appears below the ontology you selected. In my case I selected to publish the wgs84 ontology under the “wgstest” name:
As shown in the figure, the ontology will be published under “https://w3id.org/def/wgstest”
If you want to update the html in Github and want to see the changes updated, you should click on the “republish” button that now replaces the old “publish” one:
Right now the ontologies are published on the OnToology server, but we will enable the publication in Github by using Github pages soon. If you want the w3id to point somewhere else, you can either contact us at ontoology@delicias.dia.fi.upm.es, or you can issue a pull request to w3id adding your redirection before the 302 redirection in our “def” namespace: https://github.com/perma-id/w3id.org/blob/master/def/.htaccess
However, several months ago purl.org stopped registering new users. Then, only a couple of months ago the website stopped allowing registering or editing the permanent urls from a user. The official response is that there is a problem with the SOLR index, but I am afraid that the service is not reliable anymore. The current purl redirects work properly, but I have no clue on whether they intend to keep maintaining it in the future. It’s a bit sad, because it was a great infrastructure and service to the community.
Fortunately, other permanent identifier efforts have been hatched successfully by the community. In this post I am going to talk a little about w3id.org, an effort launched by the W3C permanent identifier community group that has been adopted by a great part of the community (with more than 10K registered ids). W3id is supported by several companies, and although there is no official commitment from the W3C for maintenance, I think it is currently one of the best options for publishing resources with a permanent id on the web.
Differences with purl.org: w3id is a bit geekier, but way more flexible and powerful when doing content negotiation. In fact, you don’t need to talk to your admin to do the content negotiation because you can do it yourself! Apart from that, the main difference between purl.org and w3id is that you don’t have a user interface to edit you purls. You do so through Github by editing there the .htaccess files.
How to use it: let’s imagine that I want to create a vocabulary for my domain. In my example, I will use the coil ontology, an extension of the videogame ontology for modeling a particular game. I have already created the ontology, and assigned it the URI: https://w3id.org/games/spec/coil#. I have produced the documentation and saved the ontology file in both rdf/xml and TTL formats. In this particular case, I have chosen to store everything in one of my repositories in Github: https://github.com/dgarijo/VideoGameOntology/tree/master/GameExtensions/CoilOntology. So, how to set up the w3id for it?
Go to the w3id repository and fork it. If you don’t have a Github account, you must create one before forking the repository.
Create the folder structure you assigned in the URI of your ontology (I assume that you won’t be rewriting somebody else’s URI, as if that is the case, the admins will likely detect it). In my example, I created the folders “games/spec/” (see in repo)
Http vs https: As a final comment, w3id uses https. If you publish something with http, it will be redirected to https. This may look as an unimportant detail, but is critical in some cases. For example, I have found that some applications cannot negotiate properly if they have to handle a redirect from http to https. An example is Protégé: if you try to load http://w3id.org/games/spec/coil#, the program will raise an error. Using https in you URI works fine with the latest version of the program (Protégé 5).
After a few days back in Madrid, I have finally found some time to write about the eScience 2014 conference, which took place last week in Guarujá, Brasil. The conference lasted for 5 days (the first two days with workshops), and it got attendants from all over the world. It was especially good to see many young people who could attend thanks to the scholarships awarded by the conference, even when they were not presenting a paper. I found a bit unorthodox that the presenters couldn’t apply for these scholarships (I wanted to!), but I am glad to see this kind of giveaway. Conferences are expensive and I was able to have interesting discussions about my work thanks to this initiative. I think this is also a reflection of Jim Gray’s will: pushing science into the next generation.
We were placed in touristic resort in Guarujá, at the beach. This is what you could see when you got out of the hotel:
Guarujá beach
And the jungle was not far away either. After a 20 minute walk you were able to arrive at something like this…
The jungle was not far from the beach either
…which is pretty amazing. However, the conference schedule was packed with interesting talks from 8:30 to 20:30 most of the days, and in general we were unable to do some sightseeing. In my opinion they could have reduced one workshop day and relax the schedule a little bit. Or at least remove the parallel sessions in the main conference. It always sucks to have to choose between two different interesting sessions. That said, I would like to congratulate everyone involved in the organization of the conference. They did an amazing job!
Another thing that surprised me is that I wasn’t expecting to see many Semantic Web people, since the ISWC Conference occurred at the same time in Italy, but I found quite a few. We are everywhere!
My talks at the conference were two, which summarized the results I achieved during my internship at the Information Sciences Institute earlier this year. First I presented a user survey quantifying the benefits of creating workflows and workflow fragments and then our approach to detect automatically common workflow fragments, tested in the LONI Pipeline (for more details I encourage you to follow the links to the presentations). The only thing that bothered me a bit was that my presentations were scheduled at strange hours. I had the last turn before the dinner for the first one, and then I was the first presenter the last day at 8:30 am for the second one. Here is a picture of the brave attendants who woke up early the last day, I really appreciated their effort :):
The brave attendants that woke up early to be at my talk at 8:30 am
But let’s get back to the workshop, demos and conference. As I introduced above, the first 2 days included workshop talks, demos and tutorials. Here are my highlights:
Workshops and demos:
Microsoft is investing on scientific workflows!: I attended the Azure research training workshop, were Mateus Velloso introduced the Azure infrastructure for creating and setting up virtual machines, web services, webs and workflows. It is really impressive how easily you are able to create and run experiments with their infrastructure, although you are limited to their own library of software components (in this case, a machine learning library). If you want to add your own software, you have to expose it as a web service.
Impressive visualizations using Excel sheets at the Demofest! All the demos belonged to Microsoft (guess who was one of the main sponsors of the conference) although I have to admit that they looked pretty cool. I was impressed by two demos in particular, the Sanddance beta and the Worldwide Telescope. The former is used to load Excel files with large datasets to play with the data, select, filter and plot the resources by different facets. Easy to use and very fluid in the animations. The latter was similar to Google Maps, but you were able to load your excel dataset (more than 300K points at the same time) and show it on real time. For example, in the demo you could draw the itineraries of several whales in the sea at different points in time, and show their movement minute after minute.
Microsoft demo session. With caipirinhas!
New provenance use cases are always interesting. Dario Oliveira introduced their approach to extract biographic information from the Brazilian Historical Biographical Dictionary at the Digital Humanities Workshop. This included not only the life of the different persons collected as part of the dictionary, but also each reference that contributed to tell part of the story. Certainly a complex and interesting use case for provenance, which they are currently refining.
Paul Watson was awarded with the Jim Gray Award. In his keynote, he talked about the social exclusion and the effect of digital technologies. Having a lack of ability to log online may stop you from having access to many services, and ongoing work on helping people with accessibility problems (even through scientific workflows) was presented. Clouds play an important role too, as they have the potential for dealing with the fast growth of applications. However, the people who could benefit the most from the cloud often do not have the resources or skills to do so. He also described e-Science Central, a workflow system for easily creating workflows in your web browser, with provenance recording and exploring capabilities and the possibility to tune and improve the scalability of your workflows with the Azure infrastructure. The keynote ended by highlighting how important is to make things fun for the user (“gamification “ of evaluations, for example), and how important eScience is for computer science research: new challenges are continuously presented supported by real use cases in application domains with a lot of data behind.
I liked the three dreams for eScience of the “strategic importance of eScience” panel:
Find and support the misfits, by addressing those people with needs in escience.
Support cross domain overlap. Many communities base their work on the work made by other communities, although the collaboration rarely happens at the moment.
Cross domain collaboration.
First panel of the conference
Conference general highlights:
Great discussion in the “Going native Panel”, chaired by Tony Hey, with experts from chemistry, scientific workflows and ornithology (talk about domain diversity). They analyzed the key elements of a successful collaboration, explaining how in their different projects they have a wide range of collaborators. It is crucial to have passionate people, who don’t lose the inertia after the grant from the project has been obtained. For example, one of the best databases for accessing chemicals descriptions on the UK came out from a personal project initiated by a minority. In general, people like to consume curated data, but very few are willing to contribute. In the end what people want is to have impact. Showing relevance and impact (or reputation, altmetrics, etc.) will grant additional collaborators. Finally, the issue of data interoperability between different communities was brought up for discussion. Data without methods is in many cases not very useful, which encourages part of the work I’ve been doing during the last years.
Awesome keynotes!! The one I liked the most was given by Noshir Contractor, who talked about “Grand Societal Challenges”. The keynote was basically about how to assemble a “dream team” of people for delivering a product/proposal, and all the analyses that had been done to determine which factors are the most influential. He started by talking about the Watson team, who built a machine capable of beating a human on TV, and continued by presenting the tendencies people have when selecting people for their own teams. He also presented a very interesting study of videogames as “leadership online labs”. In videogames very heterogeneous people meet, and they have to collaborate in groups in order to be successful. The takeaway conclusion was that diversity in a group can be very successful, but it is also very risky and often it ends in a failure. That is why people tend to collaborate with people they have already collaborated with when writing a proposal.
The keynote by Kathleen R. McKeown was also amazing. She presented a high level overview of the work in NLP developed in their group concerning summarization of news, journal articles, blog posts, and even novels! (which IMO has a lot of merit without going into the detail). She presented co-reference detection of events, temporal summarization, sub-event identification and analysis of conversations in literature, depending on the type of text being addressed. Semantics can make a difference!
New workflow systems: I think I haven’t seen an eScience conference without new workflow systems being presented 😀 In this case the focus was more on the efficient execution and distribution of the resources. Dispel4py and Tigres workflow systems were introduced for scientists working in Python.
Cross domain workflows and scientific gateways:
Antonella Galizia presented the DRIHM infrastructure to set up Hydro-Meteorological experiments in minutes. Impressive, as they had to integrate models for meteorology, hydrology, pluviology and hydraulic systems, while reusing existent OGC standards and developing a gateway for citizen scientists. A powerful approach, as they were able to do flooding predictions on in certain parts of Italy. According to Antonella, one of the biggest challenges on achieving their results was to create a common vocabulary which could be understood by all the scientists involved. Once again we come back to semantics…
Rosa Filgueira presented another gateway, but for vulcanologists and rock physicists. Scientists often have problems to share data among different disciplines, even if they belong to the same domain (geology in this case). This is because every lab often records their data in a different way.
Finally, Silvia Olabarriaga gave an interesting talk about workflow management in astrophysics, heliophysics and biomedicine, distinguishing the conceptual level (user in the science gateway), abstract level (scientific workflow) and concrete level (how the workflow is finally executed on an infrastructure), and how to capture provenance at these different granularities.
Other more specific work that I liked:
A tool for understanding the copyright in science, presented by Richard Hoskings. A plethora of different licenses coexist in the Linked Open Data, and it is often difficult to understand how one can use the different resources exposed in the Web. This tool helps on guiding the user about the possible consequences of using a given resource or another in their applications. Very useful to detect any incompatibility on your application!
An interesting workflow similarity approach by Johannes Starlinger, which improves the current state of the art by making efficient matching on workflows. Johannes said they would release a new search engine soon, so I look forward to analyzing their results. They have published a corpus of similar workflows here.
Context of scientific experiments: Rudolf Mayer presented the work made on the Timbus project to capture the context of scientific workflows. This includes their dependencies, methods and data under a very fine granularity. Definitely related to Research Objects!
An agile annotation of scientific texts to identify and link biomedical entities by Marcus Silva, with the particularity of being capable of loading very large ontologies to do the matching.
Workflow ecosystems in Pegasus: Ewa Deelman presented a set of combinable tools for Pegasus able to archive, distribute simulate and re-compute efficiently workflows. All tested with a huge workflow in astronomy.
Provenance is still playing an important role in the conference, with a whole session for related papers. PROV is being reused and extended in different domains, but I still have to see an interoperable use across different domains to show its full potential.
Conference dinner and dance with a live band
In summary, I think the conference has been a very positive experience and definitely worth the trip. It is very encouraging to see that collaborations among different communities are really happening thanks to the infrastructure being developed on eScience, although there are still many challenges to address. I think we will see more and more cross domain workflows and workflow ecosystems in the next years, and I hope to be able to contribute with my research.
I also got plenty of new references to add to the state of the art of my thesis, so I think that I also did a good job by talking to people and letting others know of my work. Unfortunately my return flight was delayed and I missed my connection back to Spain, converting my 14 hour flight home to almost 48 hours. Certainly the longest journey from any conference I have assisted to.
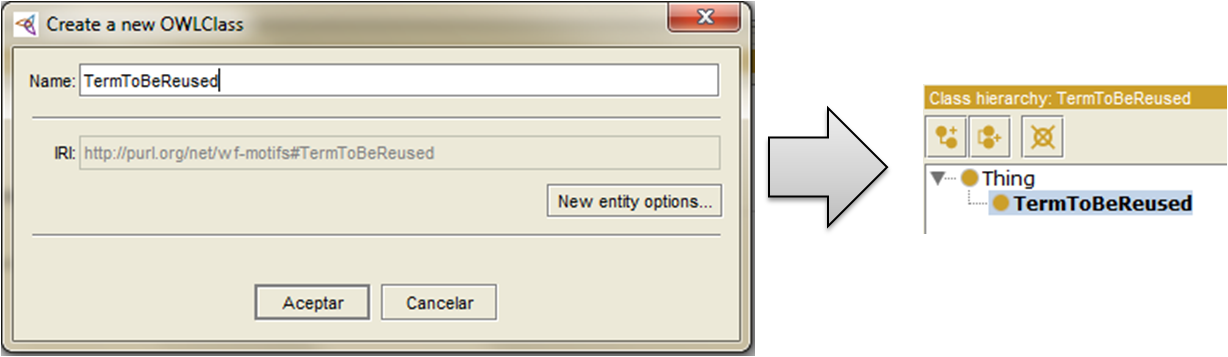
And we finally arrive to the last part of the tutorial, which is a set of guidelines on how to reuse other vocabularies (i.e., how your vocabulary should link to other vocabularies). Reuse is not only related to publication, but also to the design of your own vocabulary. As a researcher, everyone knows that it is better not to reinvent the wheel. If an existent vocabulary covers with its terms part of what you want to cover in your competency questions (or system requirements), why should you redefine the same terms again and again?
In order to avoid this issue, you can either import that vocabulary into yours, which will bring the whole imported vocabulary as part of your ontology (like a module), or you could either extend only those properties and classes that you are going to reuse, without adding all the terms of the reused vocabulary as part of your ontology.
Which way is better? It depends: on one hand, I personally like to extend the vocabularies that I reuse when the terms being expanded are not many. Importing a vocabulary often makes it more difficult to present, and for someone loading the ontology, it could be very confusing to browse across many terms not being used in my domain.
Reusing concepts from other ontologies simplifies your domain model, as you import just those being extended.
On the other hand, if you plan to reuse most of the vocabulary being imported, for example by creating a profile of a vocabulary for a specific domain, the import option is the way to go.
Importing an ontology makes it on one hand easy to reuse, but on the other (in some cases) it makes your ontology more difficult to understand.
Another advice is to be careful with the semantics. I personally don’t like to mess up with the concepts defined by other people. If you need to add your own properties taking as domain or ranges classes defined by other people, you should specialize those classes in your ontology. Imagine an example where I want to reuse the generic concept from the PROV ontology prov:Entity for refering to the provenance of digital entities (which is my sample domain). If I want to add a property that has domain digital entity (like hasSize), then I should specialize the term prov:Entity with a subclass for my domain (in this case digitalEntity subClassOf Entity). If I just assert properties on the general term (prov:Entity) then I may be overextending my property to other domains than those I may have thought, and what is worse: I may be modifying a model which I haven’t defined originally.
But where to start looking if you want to reuse a vocabulary? There are several options:
Linked Open Vocabularies (LOV ): A set of common vocabularies that are distributed and organized in different categories. Different metrics for each vocabulary are displayed regarding its metadata and reuse, which will help you to determine whether it is still in unse or not.
The W3C standards: When building a vocabulary it is allways good to look up if a standard on that domain already exists!
Swoogle and Watson will allow you to search for terms on your domain and suggest you existent approaches.
With this post the tutorial ends. I hope it served to clarify at least a couple of things regarding vocabulary/ontology publication in the web. If you have any questions please leave them on the comments and I’ll be happy to help you.
Do you want more information regarding ontology importing and reuse? Check out these papers (thanks Maria and Melanie for the pointers):
After a long summer break in blogging, I’m committed to finishing this tutorial. In thispost I’ll explain why and how to dereference your vocabulary when publishing it in the Web.
But first, why should you dereference your vocabulary? In part 2 I showed how to create a permanent URL (purl) and redirect it to the ontology/vocabulary we wanted to publish (in my case it was http://purl.org/net/wf-motifs). If you followed the example you would have seen that now when you enter the purl you created in the web browser it redirects you to the ontology file. However if you enter http://purl.org/net/wf-motifs you will be redirected to the html documentation of the ontology. When entering the same URL in Protégé, the ontology file will be loaded in the system. By dereferencing the motifs vocabulary I am able to choose what to deliver depending on the type of request received by the server on a single resource: RDF files for applications and nice html pages for the people looking for information about the ontology (structured content for machines, human readable content for users).
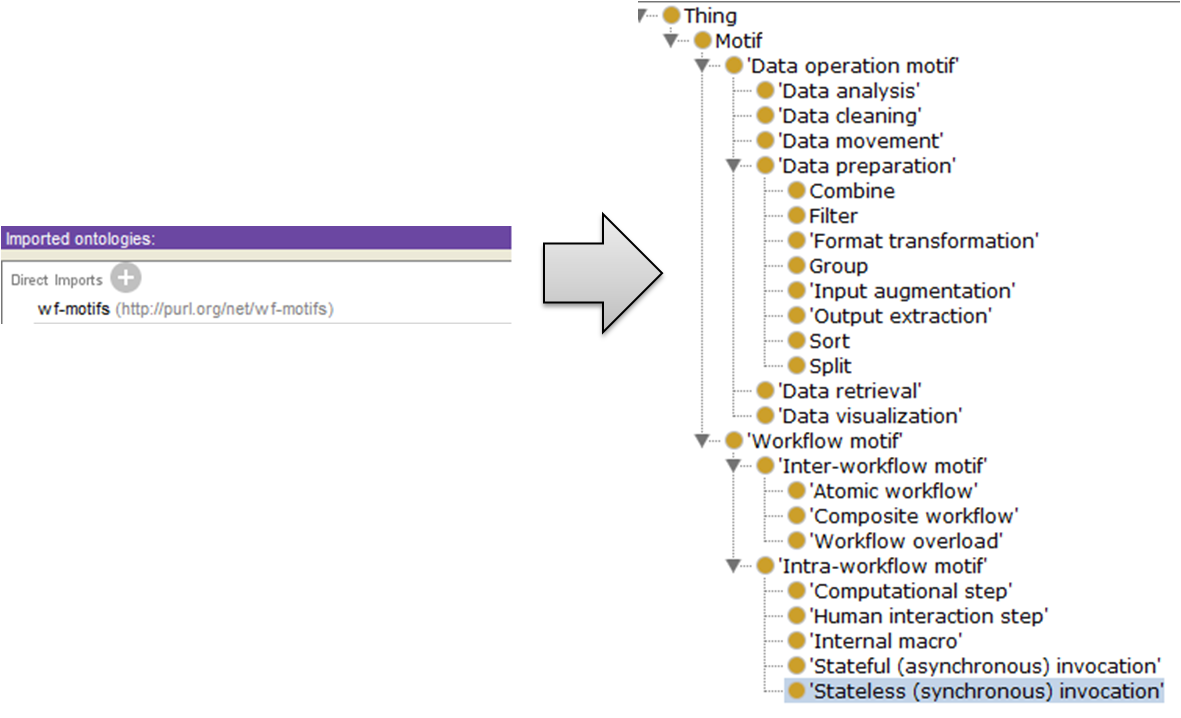
Additionally, if you have used the tools I suggested in previous posts, when you ask for a certain concept the browser will take you to the exact part of the document defining it. For example, if you want to know the exact definition for the concept “FormatTransformation” in the Workflow Motif ontology, then you can paste its URI (http://purl.org/net/wf-motifs#FormatTransformation) in the web browser. This makes the life easier for users when browsing and reading your ontology.
And now, how do you dereference your vocabulary? First, you should set the purl redirection as a redirection for Semantic Web resources (add a 303 redirection instead a 302, and add the target URL where you plan to do the redirection). Note that you can only dereference a resource if you control the server where the resources are going to be delivered. The screenshot below shows how it would look in purl for the Workflow Motifs vocabulary. http://vocab.linkeddata.es/motifs is the place our system admin decided to store the vocabulary.
Purl redirection
Now you should add the redirection itself. For this I always recommend having a look into the W3C documents, which will guide you step by step on how to achieve this. In this case in particular we followed http://www.w3.org/TR/swbp-vocab-pub/#recipe3, which is a simple redirection for vocabularies with a hash namespace. You have to create an htaccess file similar to the one pasted below. In my case the index.html file has the documentation of the ontology, while motif-ontology1.1.owl contains the rdf/xml encoding. If a ttl file exists, you can also add the appropriate content negotiation. All the files are located in a folder called motifs-content, in order to avoid an infinite loop when dealing with the redirections of the vocabulary:
# Turn off MultiViews
Options -MultiViews
# Directive to ensure *.rdf files served as appropriate content type,
# if not present in main apache config
AddType application/rdf+xml .rdf
AddType application/rdf+xml .owl
#AddType text/turtle .ttl #<---Add if you have a ttl serialization of the file
# Rewrite engine setup
RewriteEngine On
RewriteBase /def
# Rewrite rule to serve HTML content from the vocabulary URI if requested
RewriteCond %{HTTP_ACCEPT} !application/rdf\+xml.*(text/html|application/xhtml\+xml)
RewriteCond %{HTTP_ACCEPT} text/html [OR]
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml [OR]
RewriteCond %{HTTP_USER_AGENT} ^Mozilla/.*
RewriteRule ^motifs$ motifs-content/index.html
# Rewrite rule to serve RDF/XML content from the vocabulary URI if requested
RewriteCond %{HTTP_ACCEPT} application/rdf\+xml
RewriteRule ^motifs$ motifs-content/motif-ontology1.1.owl [R=303]
# Rewrite rule to serve turtle content from the vocabulary URI if requested
#RewriteCond %{HTTP_ACCEPT} text/turtle
#RewriteRule ^motifs$ motifs-content/motifs_ontology-ttl.ttl [R=303]
# Choose the default response
# ---------------------------
# Rewrite rule to serve the RDF/XML content from the vocabulary URI by default
RewriteRule ^motifs$ motifs-content/motif-ontology1.1.owl [R=303]
Note the redirections when the owl is being requested. If you have a slash vocabulary, you will have to follow the aforementioned W3C document for further instructions.
Now it is time to test that everything works. The easiest way is just to paste the URI of the ontology in Protégé and in your browser and check that in one case it loads the ontology properly and in the other you can see the documentation. Another possibility is to use curl like this: curl -sH “Accept: application/rdf+xml” -L http://purl.org/net/wf-motifs(for checking that the rdf is obtained) or curl -sH “Accept: text/html” -L http://purl.org/net/wffor the html.
Finally, you may also use the Vapour validator to check that you have done the process correctly. After entering your ontology URL, you should see something like this:
Vapur validation
Congratulations! You have dereferenced your vocabulary successfully 🙂
Vocabularies and ontologies have been developed in the last years for modeling different use cases in heterogeneous domains. These vocabularies/ontologies are often described in journal publications and conferences, which reflect the rationale of the design decisions taken during their development. Now that everyone is talking about Linked Data, I have found myself looking for guidelines to properly publishing my vocabularies on the web, but unfortunately the required documentation is scattered through many different places.
First things first. What do I mean by properly publishing a vocabulary? By that I refer to making it an accessible resource, both human and machine readable, with documentation with examples and with its license specified. In this regard, there have been two initiatives for gathering the requirements I am trying to address in this tutorial: the 5-Star Vocabulary requirements by Bernard Vatant and the AMOR manifesto by Raúl García-Castro. Both of these approaches are based in Tim Berners Lee’s Linked Data 5 star rating, and complement each other. In this tutorial (which will be divided in 5 parts), I will cover possible solutions to address each of their requirements, further described below (quoting the original posts).
– Requirements of the AMOR manifesto (A):
(A1) The ontology is available on the web (whatever format) but with an open licence
(A2) All the above, plus: available as machine-readable structured data (e.g., CycL instead of image scan of a table)
(A3) All the above, plus: non-proprietary format (e.g., OBO instead of CycL)
(A4) All the above, plus: use open standards from the W3C (RDF Schema and OWL)
(A5) All the above, plus: reuse other people’s ontologies in your ontology
– Requirements of the 5 start vocabulary principles (P)
(P1)Publish your vocabulary on the Web at a stable URI
(P2) Provide human-readable documentation and basic metadata such as creator, publisher, date of creation, last modification, version number
(P3) Provide labels and descriptions, if possible in several languages, to make your vocabulary usable in multiple linguistic scopes
(P4) Make your vocabulary available via its namespace URI, both as a formal file and human-readable documentation, using content negotiation
(P5) Link to other vocabularies by re-using elements rather than re-inventing.
The tutorial will be divided in 5 parts (plus this overview):